
티스토리 뷰
아래 노트와 같이 보기 위해 쓴 글이다.
[TF] PetFinder: ViT+Cls [TPU][Train] 😺
Explore and run machine learning code with Kaggle Notebooks | Using data from PetFinder.my - Pawpularity Contest
www.kaggle.com
아이디어 :
- 회귀 대신 분류를 쓰자.
- Pawpularity 0~100 점을 0~1로 정규화하자.
- RootMeanSquaredError 대신 BinaryCrossentropy loss를 사용.
- 역정규화를 거친 예측값들을 대회의 평가 기준(RMSE)을 통해 평가하자.
- CNN 대신 Transformer를 사용!
- 이미지 feature만 사용.
- Wandb를 통해서 어떤 시도들이 좋은 성능을 내는지 추적이 가능하고, Attention-MAP을 통해 에러를 분석 분석할 수 있음.
개요 :
Augmentations :
- Random - Horizontal Flip
- Random - Brightness, Contrast, Hue(색상), Saturation(채도)
- Coarse Dropout
WandB Integration :
Attention-MAP :
Train Vs OOF Distribution :
Import Libraries
!pip install -q vit-keras
from vit_keras import vitVision Transformer 패키지를 설치하고 import만 해주면 이미지넷2012를 기준으로 pretained된 weights 값들을 바로 사용할 수 있다.
Wandb
MLOps 플랫폼으로 더 나은 모델을 위해 쉽고 빠르게 개선할 수 있도록 머신 러닝을 통한 모든 작업 내용들을 시각화하고 추적하고 비교 분석할 수 있도록 도와준다. 작업에 대한 전반적인 정보들이 중앙화된 대시보드 위에서 실시간으로 확인되고 관리를 용이하게 해 주기 때문에 굉장히 파워풀한 툴이라고 생각한다.
Configuration
프로젝트 전반으로 사용해줄 설정값과 각종 파라미터들에 대한 정보를 class 안에 모아서 작성해두었다.
Set Seed for Reproducibility
난수를 발생시킬 다양한 주체들, 파이썬, 넘파이, 텐서 플로우 등등. 모든 모듈에 대하여 일정한 재현성을 위해 SEED를 지정해줘야 하는데 이와 같은 방식으로 해줘야 한다. (참고)
def seeding(SEED):
np.random.seed(SEED) #numpy
random.seed(SEED) #python
os.environ['PYTHONHASHSEED'] = str(SEED) # set PYTHONHASHSEED env var at fixed value
# os.environ['TF_CUDNN_DETERMINISTIC'] = str(SEED)
tf.random.set_seed(SEED) #tensorflow
print('seeding done!!!')
seeding(CFG.seed)TPU Configs
험난한 캐글을 탐험하기 위해 컴퓨터의 성능은 제법 중요하다. 그래서 얼마나 좋은 gpu를 써야하는데?...
- RTX 8000: 48 GB VRAM, ~$5,500.
- RTX 6000: 24 GB VRAM, ~$4,000.
- Titan RTX: 24 GB VRAM, ~$2,500.
캐글의 데이터가 두 자리 크게는 세 자리의 GB가 되어가는 추세고, Sota를 차지한 모델들도 매우 무거워지고 있다. 딥러닝이니까 어찌 보면 당연한 현상인데... 그럼 개인은 캐글 못하게 된 건가 싶겠지만 이 부분에서 큰 도움을 줄 수 있는 것이 TPU다.
Meta Data
각 데이터마다 image_path 칼럼과 imgsize[ 'width', 'height'] 칼럼 2개를 추가해주면서 train set과 test set을 load하여 준비했다.
Light EDA
EDA가 귀찮은 사람들에게 Pandas-Profiling 기능을 사용해보라고 추천해주고 있다. 기본적인 EDA과정을 모두 시행해준다. 참 세상 많이 좋아졌다.
칼럼 별 최대, 최소, 평균 등의 값으로 분포 파악이 가능하고 correlations, 결측 값 등 모두 확인이 가능하다.
Data Split
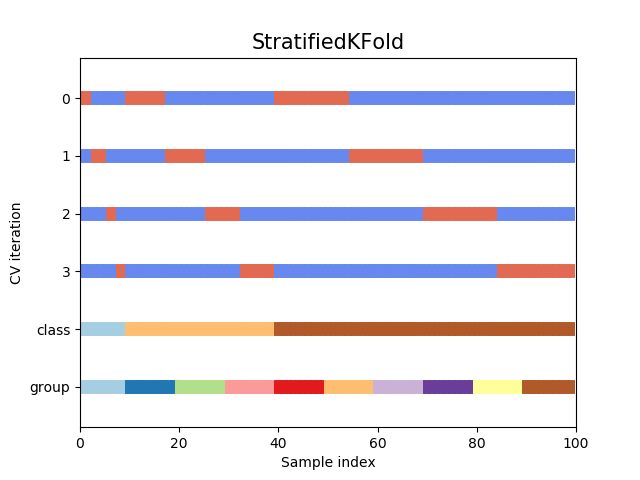
StratifiedKFold
Pawpularity를 분포형태로 표현하여 데이터를 StratifiedKFold 방식으로 나누어주었다.
기존 Kfold는 fold마다 일정한 분포를 유지할 수 없어 특히, imbalanced한 데이터에서 fold를 나눌 경우 아주 운이 나쁘게 특정 class가 전혀 포함되지 않는 fold가 생길 수도 있다. 다시 말해, 어떤 fold에서는 특정 class값에 대한 학습이 전혀 이루어지지 않는다는 의미다. 그래서 이러한 단점을 커버하기 위해서 StratifiedFold를 사용하면 각 클래스를 각 fold안으로 균등하게 나눠서 사이좋게 가져간다. 그럼 모든 fold는 동일한 class의 분포로 갖게 된다.
log2 ?
num_bins = int(np.floor(1 + np.log2(len(df))))정보이론은 시그널에 존재하는 정보의 양을 측정하는 응용수학의 한 갈래. 머신러닝에서는 해당 확률분포의 특성을 알아내거나 확률분포 간 유사성을 정량화하는 데 쓰인다.
정보이론의 핵심 아이디어는 잘 일어나지 않는 사건(unlikely event)은 자주 발생하는 사건보다 정보량이 많다(informative)는 것!!! 반대로 보장된 사건은 정보량이 zero~
섀넌 엔트로피(Shannon Entropy)
I(x)=−logP(x)
위의 아이디어를 식으로 표현하면 확률분포에 음의 로그를 취한 수식인데, 동전을 던져 앞면이 나오는 사건과 주사위를 던져 눈이 1이 나오는 사건, 두 개의 정보량을 비교해보자. 전자의 정보량은 1, 후자는 2.5849가 된다. 다시 말해, 주사위 눈이 1이 나올 사건은 동전의 앞면이 나오는 사건보다 덜 자주 발생하므로 더 높은 정보량을 갖는다는 의미.
위 식에서 밑이 2인 로그일 경우 정보량의 단위는 섀넌 또는 비트(bit)라고 한다. 자연상수를 밑으로 할 경우 내트(nat)라고 부른다. 머신러닝에서는 주로 밑을 자연상수로 한다.
섀넌 엔트로피(Shannon entropy)는 모든 사건 정보량의 기대값을 뜻한다.
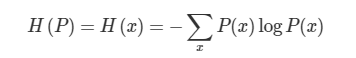
동전이 2개일 경우 결과의 경우의 수는 4가지. 섀넌 엔트로피는 2비트가 됩니다.
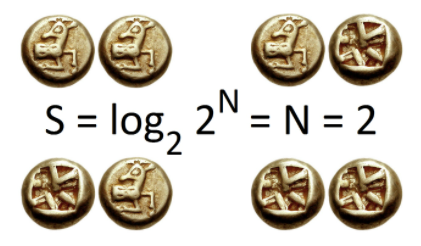
Data Augmentation
어떤 축을 기준으로 좌표 변환을 할지에 따라 약간의 모양 차이가 발생하지만 아래와 같은 기본 꼴을 가지고 있다.
Data Pipeline
- build_decoder - 이미지 파일을 tensor로 변환, resize, float32 타입으로 변환, 정규화, reshape의 과정을 마친다. 또한 Pawaularity도 정규화.
- build_augmenter - 앞서 Data augmentation에서 작성한 transform을 랜덤하게 적용하도록 한 번에 묶었고, 이외에도 좌우, 상화 반전, 색상, 채도, 밝기 등을 변화시킴. (* tf.clip_by_value는 텐서값을 내가 지정한 min과 max로 제한하여 다시 채워주는 기능을 한다.)
- build_dataset - 캐싱을 이용하여 data를 다룰 때 속도를 빠르게 해 줌.
Loss Function
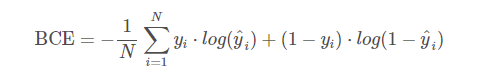
참 또는 거짓에 따라 엔트로프 차이에 의한 Loss를 측정하는 방식. Prediction과 truth 간의
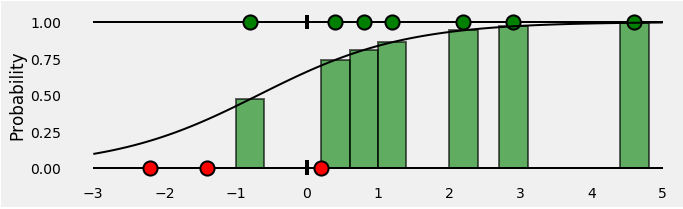
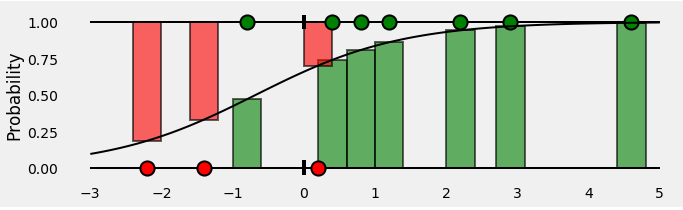
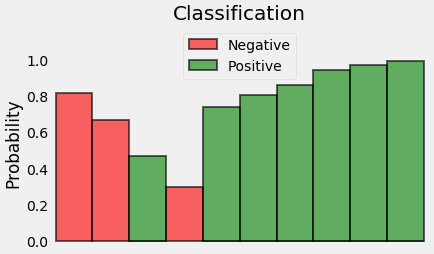
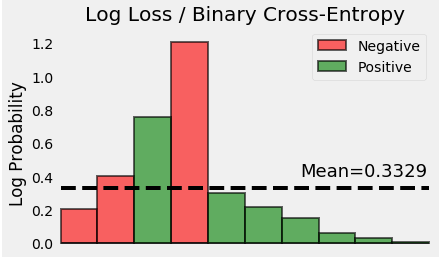
Metric(측정 항목)
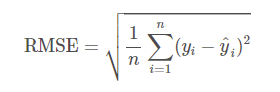
0~1의 범위로 정규화해주었던 Pawpularity 값을 다시 0~100의 값을 갖도록 Denormalize해주고 loss를 구한다.
RMSE를 쓰는 이유는 큰 오차에 대해서 패널티를 줄 수 있다. (ex. 2,3,100이라는 오차가 있을 때, MAE값은 35, RMSE값은 57.8이 나온다.)
Build Model : ViT
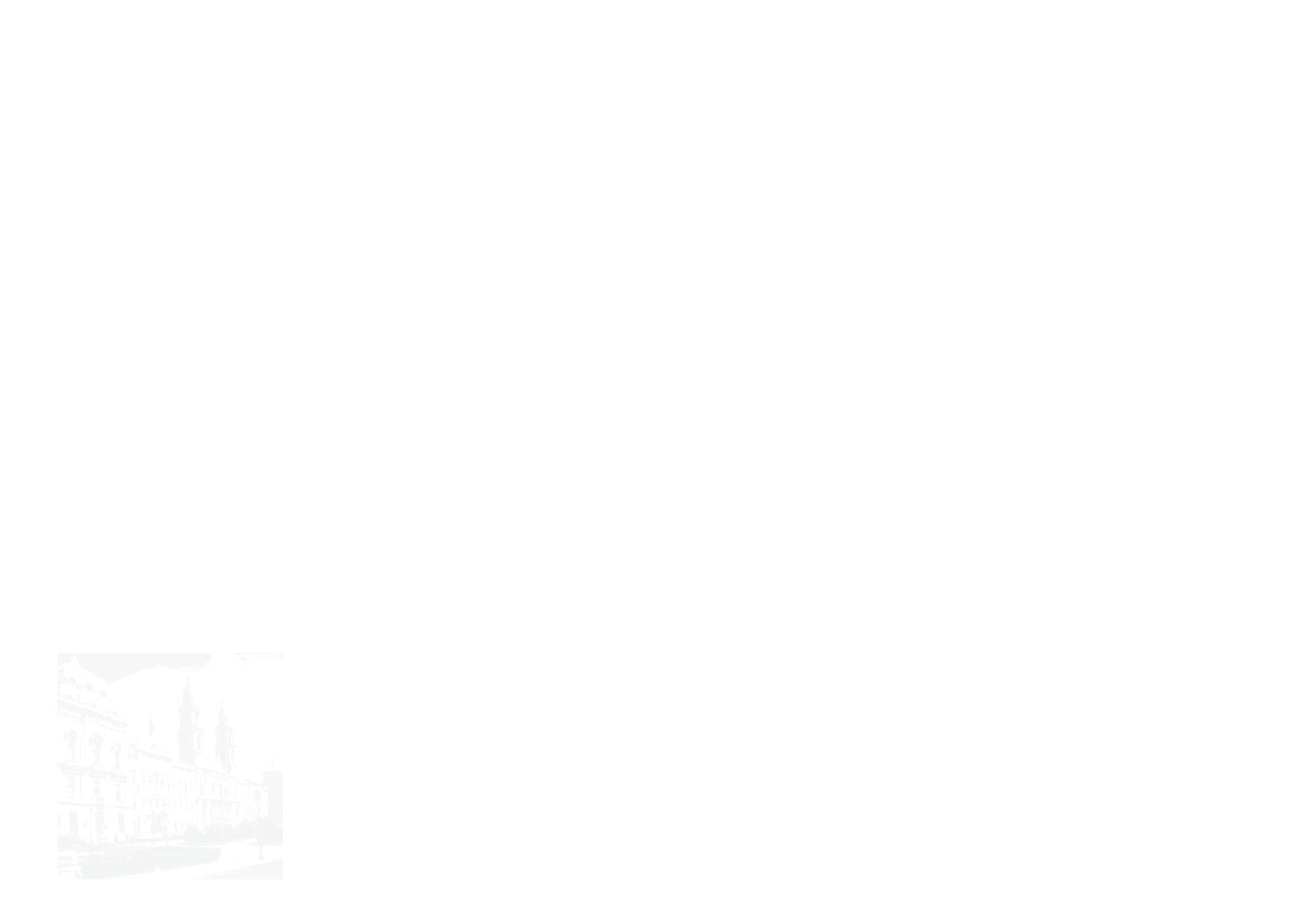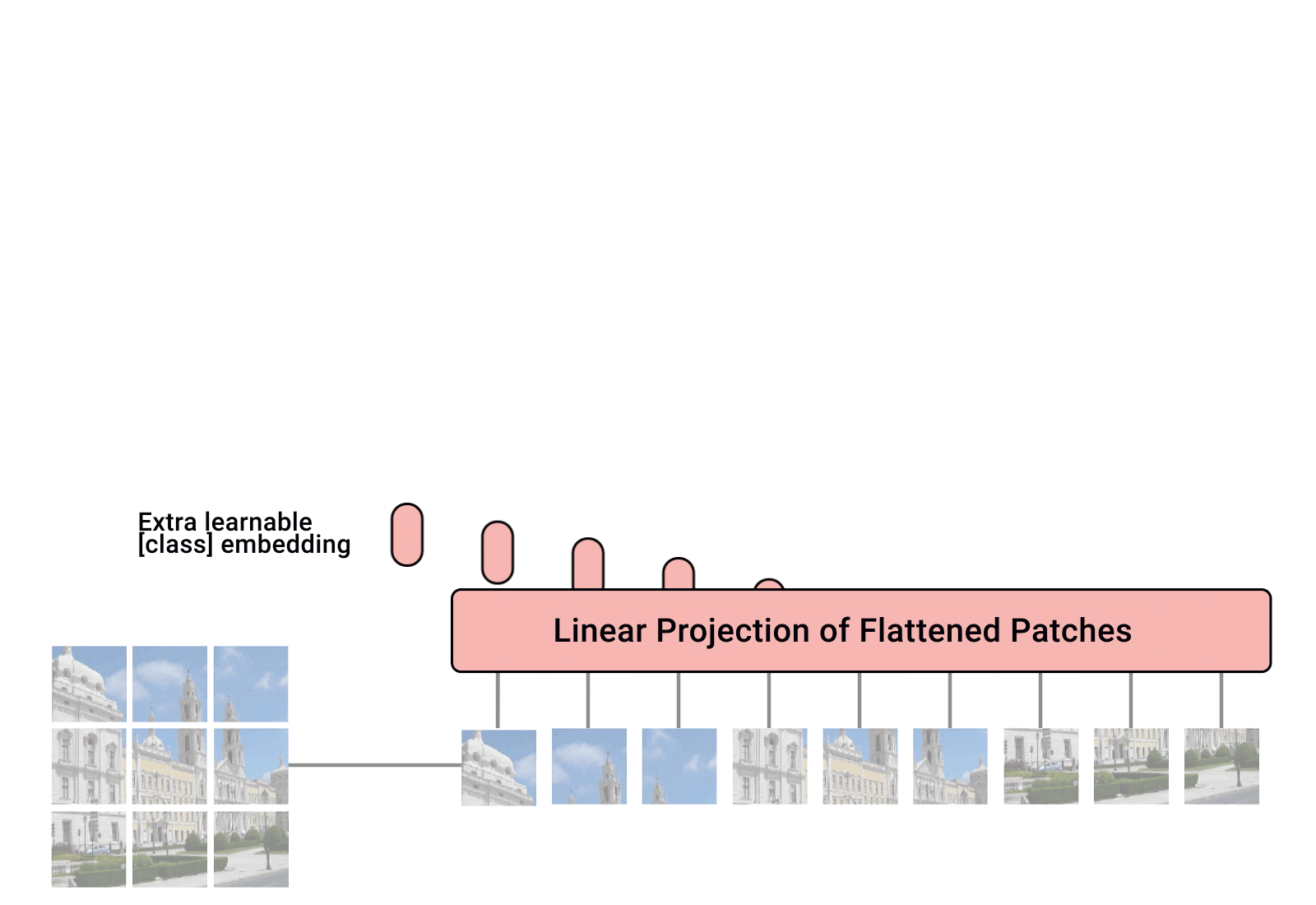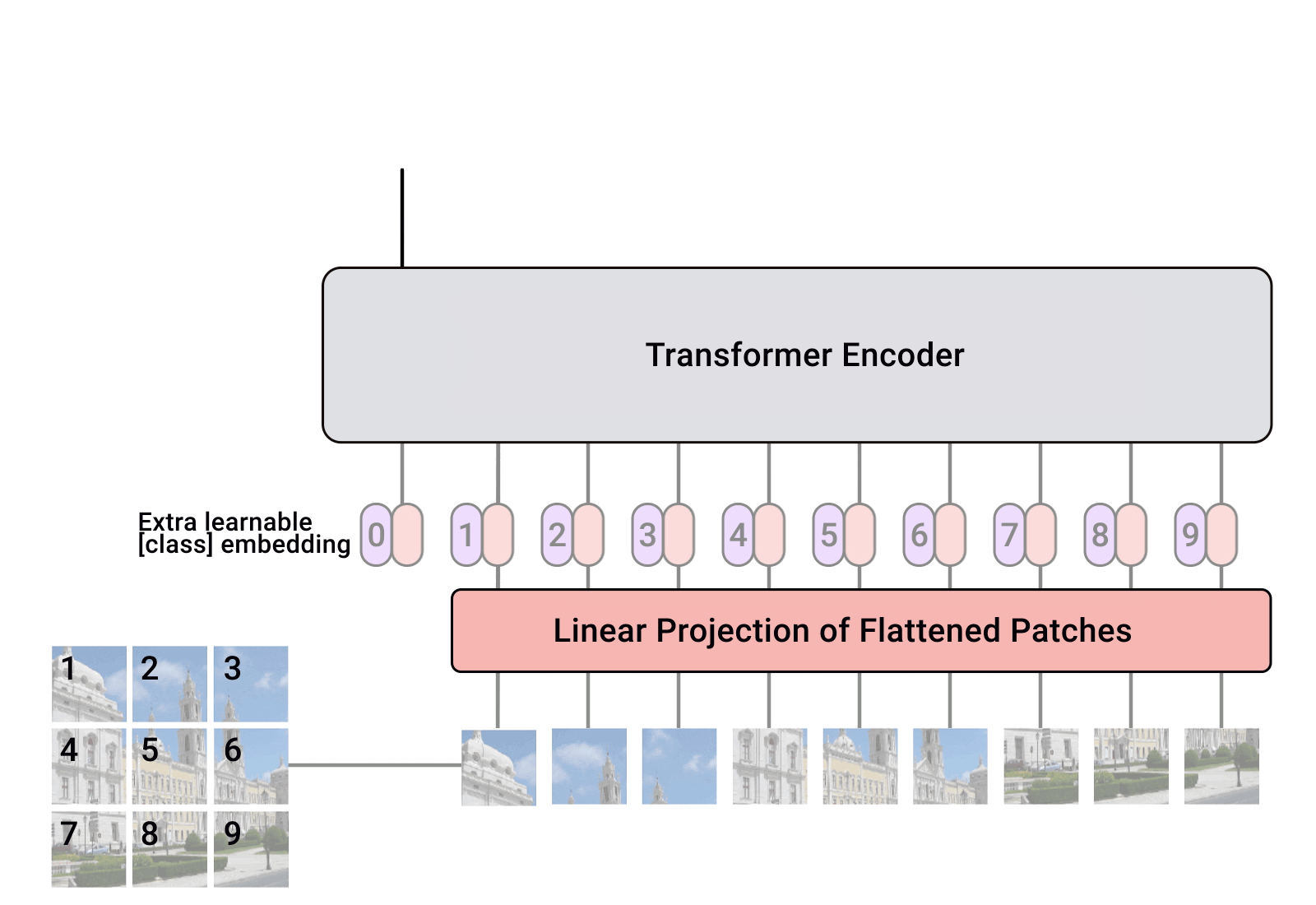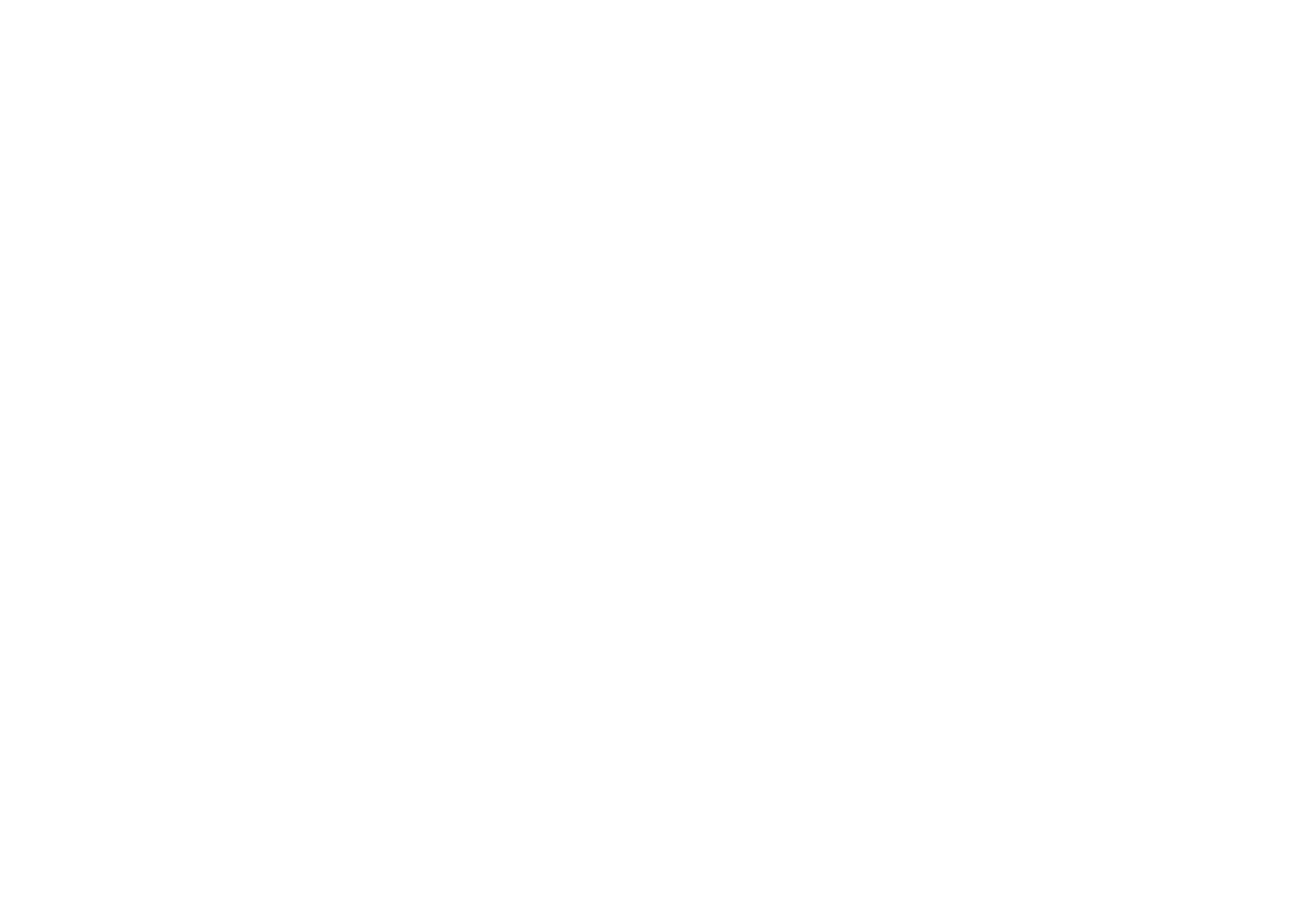
ViT를 간단히 설명하면 input 이미지를 16x16 크기의 순차적인 패치들로 나누고 패치를 하나의 단어로 생각하여 학습하는 모델이다. 마치 NLP Transformer(변환기)가 일련의 단어들을 임베딩하여 벡터를 생성하듯 ViT도 똑같다.(특히, transformer encoder만 사용한다는 점이 BERT와 동일.)
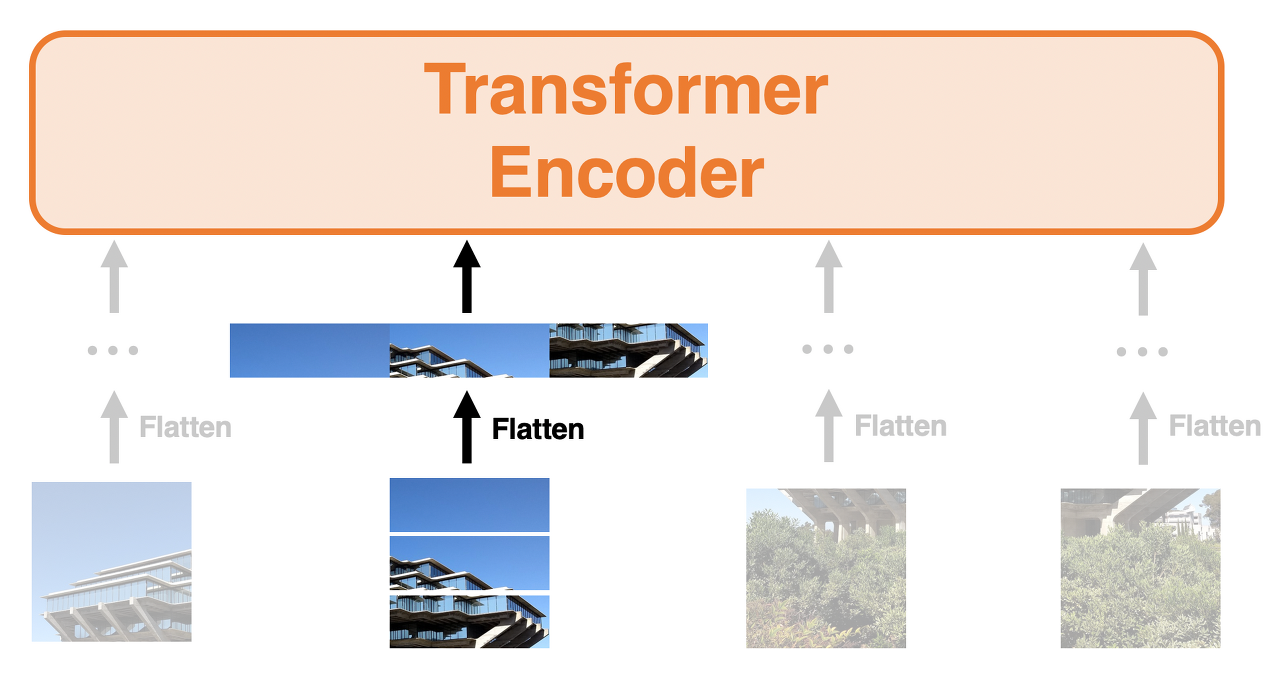
각 패치를 단어처럼 다루기 때문에 패치를 벡터에서 flatten하는 과정이 필요하다. 위 그림처럼 flatten을 실행하는 것이고 이를 수학적인 기호를 사용하여 나타내 보자. 원래 이미지가 아래와 같을 때, (H/W/C : Heights/Weights/Channels)
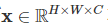
Flatten한 뒤부터 ViT에 입력하는 것은 아래와 같이 벡터로 처리하여 입력하는 것이다.
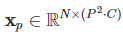
여기서 N은 패치 수이고, P는 패치의 크기를 의미한다. 여기서 패치는 정사각형이므로, 즉 N은 다음과 같이 표현할 수 있다.
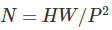
위 이미지의 원본 이미지의 사이즈가 H,W = 512라고 한다면, N은 1024, P는 16이 된다.
총 patch embedding 수는 1024 x 768(P^2 X C) = 786,432
마지막 output layer는 두 개의 dense layer로 되어있고, pawpularity 값만 출력받도록 하는 모델이기 때문에 마지막 줄은 출력이 1로 되어있다.
out = tf.keras.layers.Dense(64,activation='selu')(out)
out = tf.keras.layers.Dense(1, activation='sigmoid')(out)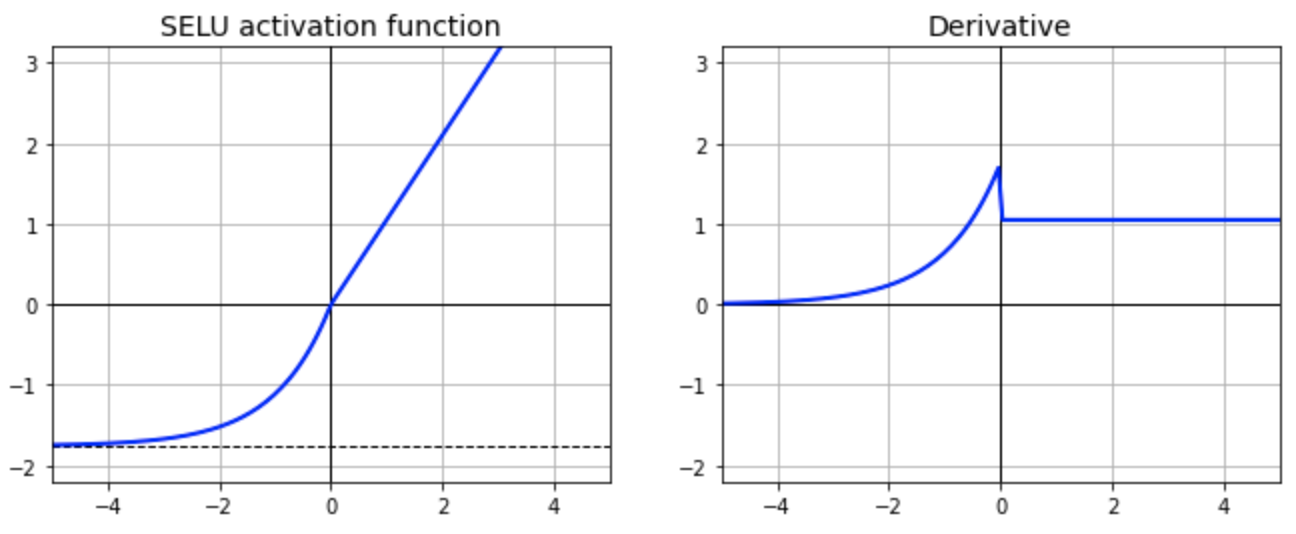
Learning-Rate Scheduler
Lr Scheduler는 미리 학습 일정을 정해두고, 그 일정에 따라 학습률을 조정하는 방법.
일반적으로는 warmup이라는 파라미터를 정하고 현재 step이 warmup보다 낮을 경우는 learning rate를 linear하게 증가 시키고, warmup 후에는 각 Lr Scheduler에서 정한 방법대로 learning rate를 update하는 방식입니다.
이번 노트북은 Epoch수가 5회로 적어서 증가하는 부분만 표현이 됩니다.
Attention Map

결과를 시각화해줄 수 있는 부분인데, 패치들과 residual connections 때문에 ViT의 처음부터 끝까지 거친 과정의 attention값을 어떻게 모두 합쳐서 이를 map으로 표현할 수 있을까가 까다로운 문제고 지금도 사실 이해를 제대로 못했는데, "Quantifying Attention Flow in Transformers" 논문에서 "attention rollout"이라는 방법을 보여주는데, Attention map에 Aij라는 값이 있고 이것은 이전 layer의 j번째 패치가 현layer의 i번째 패치에 얼마나 attention을 부여하는지를 나태내므로 Tranformer 전반의 인코더 블락의 attention map을 합치는 방법을 제안한다.
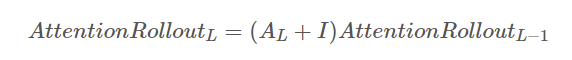
reshaped = reshaped.mean(axis=1)
# From Section 3 in https://arxiv.org/pdf/2005.00928.pdf ...
# To account for residual connections, we add an identity matrix to the
# attention matrix and re-normalize the weights.
reshaped = reshaped + np.eye(reshaped.shape[1])
reshaped = reshaped / reshaped.sum(axis=(1, 2))[:, np.newaxis, np.newaxis]이 내용에 대해선 다음에 더 다루어 보겠다!
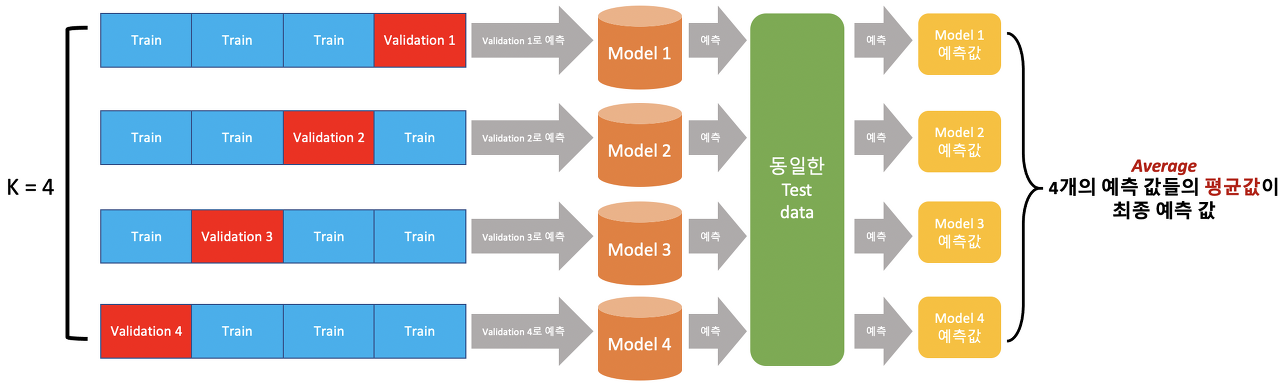
Train Model
CV = 5 folds 로 훈련한 모델 5개를 얻게 될 것이고, WandB 대시보드를 살펴보고 best model을 얻을 예정.
Modelcheckpoint를 이용해서 최적의 모델을 저장해둔다. save_best_only가 true일 때, 가장 좋은 결과로 갱신해서 저장하는 파라미터이고, save_weights_only는 false로 해줘야 모델 전체를 저장해준다. True일 경우에는 딱 weights만 저장함.
# SAVE BEST MODEL EACH FOLD
sv = tf.keras.callbacks.ModelCheckpoint(
'fold-%i.h5'%fold, monitor='val_rmse', verbose=CFG.verbose, save_best_only=True,
save_weights_only=False, mode='min', save_freq='epoch')
callbacks = [sv,get_lr_callback(CFG.batch_size)]
if CFG.wandb:
callbacks.append(WandbCallback)
OOF 와 TTA
최고 성능을 낸 체크포인트로 저장한 각각의 모델을 통해
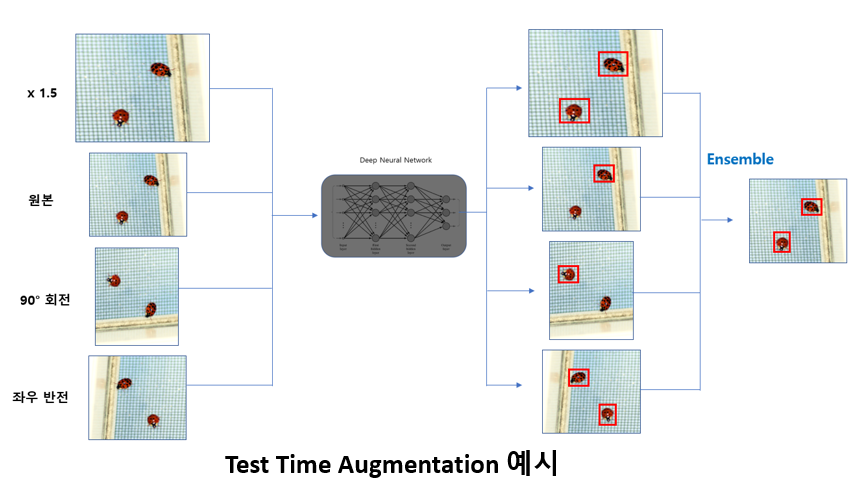
보통 Training 단계에서 많이 사용되지만 위의 그림처럼 Test 단계에서도 사용이 가능하며, 이를 Test-Time Augmentation (TTA) 라고 부른다. 한 장의 Test image를 여러 장으로 증강시켜 inference를 시킨 뒤 나온 output을 ensemble하는 방식.
# PREDICT OOF USING TTA
print('Predicting OOF with TTA...')
ds_valid = build_dataset(valid_paths, labels=None, cache=False, batch_size=CFG.batch_size*REPLICAS*2,
repeat=True, shuffle=False, augment=True if CFG.tta>1 else False)
ct_valid = len(valid_paths); STEPS = CFG.tta * ct_valid/CFG.batch_size/2/REPLICAS
pred = model.predict(ds_valid,steps=STEPS,verbose=CFG.verbose)[:CFG.tta*ct_valid,]
oof_pred.append(np.mean(pred.reshape((ct_valid,-1,CFG.tta),order='F'),axis=-1)*100.0 )
# GET OOF TARGETS AND idS
oof_tar.append(valid_df[CFG.target_col].values[:(1000 if CFG.debug else len(valid_df))])
oof_folds.append(np.ones_like(oof_tar[-1],dtype='int8')*fold )
oof_ids.append(valid_df.Id.values)
# PREDICT TEST USING TTA
print('Predicting Test with TTA...')
ds_test = build_dataset(test_paths, labels=None, cache=True,
batch_size=(CFG.batch_size*2 if len(test_df)>8 else 1)*REPLICAS,
repeat=True, shuffle=False, augment=True if CFG.tta>1 else False)
ct_test = len(test_paths); STEPS = 1 if len(test_df)<=8 else (CFG.tta * ct_test/CFG.batch_size/2/REPLICAS)
pred = model.predict(ds_test,steps=STEPS,verbose=CFG.verbose)[:CFG.tta*ct_test,]
preds[:ct_test, :] += np.mean(pred.reshape((ct_test,-1,CFG.tta),order='F'),axis=-1) / CFG.folds*100 # not meaningful for DIBUG = True
참고 자료와 읽을거리들
<리뷰한 코드>
[TF] PetFinder: ViT+Cls [TPU][Train] 😺
Explore and run machine learning code with Kaggle Notebooks | Using data from PetFinder.my - Pawpularity Contest
www.kaggle.com
- 정보이론 기초 / ratsgo's blog / https://ratsgo.github.io/statistics/2017/09/22/information/
- [손실함수] Binary Cross Entropy / Curt Park's blog / https://curt-park.github.io/2018-09-19/loss-cross-entropy/
- [분류기/손실함수]Binary Cross-Entropy / Log loss / 인텔리즈 공식 블로그 / https://blog.naver.com/intelliz/221707985006
- (CLIP) 텍스트 정보를 이용한 Visual Model Pre-training / Inforience / https://inforience.net/2021/02/09/clip_visual-model_pre_training/
- Vision Transformer(1 - 2) / 홍러닝 블로그 / https://hongl.tistory.com/232 / https://hongl.tistory.com/233
- Vision Transformer(3) - Attention Map / 홍러닝 블로그 / https://hongl.tistory.com/234
'AI,ML,DL' 카테고리의 다른 글
| repeat, shuffle, batch에 관하여 (0) | 2022.03.31 |
|---|---|
| 데이터 시각화와 전처리(kaggle 포켓몬 데이터) (2) | 2022.01.14 |
| CNN모델에 대하여 : dogs&cats classifier (0) | 2022.01.12 |
- Total
- Today
- Yesterday
- EDA
- 텐서플로우
- 데이터전처리
- cnn
- 아이펠
- 삶 #성공
- 강아지고양이분류기
- GAN #FID #StyleGAN #StyleGAN2
- 분류기
- 토스 #독서 #유난한도전 #스타트업
- AIFFEL
- python #패러다임
- 포켓몬
- K-Digital
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |