
티스토리 뷰
오늘은 귀여운 존재 두 가지를 분류하는 코드를 쭉 보면서 여러 개념에 대해 공부해보려 한다. 우선은 여러 데이터 샘플들이 있는 TensorFlow Datasets에서 dogs&cats 데이터를 사용할 거고 그 외 여러 데이터도 한번 살펴보면 좋을 것 같다.
데이터 세트 | TensorFlow Datasets
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trade
www.tensorflow.org
아래는 CNN에서 필수적으로 import하는 녀석들. 외워두면 좋을 것 같다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D모델은 이런식으로 사용해볼 예정.
model = Sequential([
Conv2D(filters=16, kernel_size=3, padding='same', activation='relu', input_shape=(160, 160, 3)),
MaxPooling2D(),
Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(units=512, activation='relu'),
Dense(units=2, activation='softmax')
])Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 160, 160, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 80, 80, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 80, 80, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 40, 40, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 40, 40, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 20, 20, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 25600) 0
_________________________________________________________________
dense (Dense) (None, 512) 13107712
_________________________________________________________________
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 13,132,322
Trainable params: 13,132,322
Non-trainable params: 0
_________________________________________________________________model.summary()
를 해주면 위와 같은 output을 볼 수 있는데, 이 의미들을 살펴보면 좋다.
첫 번째 차원은 데이터의 개수를 나타낸다. 모델 정보만 본 상황이라 데이터 값은 None 기호로 표시된다. None은 배치(batch) 사이즈에 따라 모델에 다른 수의 입력이 들어올 수 있음을 나타낸다.
데이터 하나의 크기는 (height, width, channel)로 3차원. 6개의 레이어를 지나면서 height와 width는 점점 작아지고, channel은 점점 커지다가, flatten 계층을 만나 25,600(20x20x64)이라는 하나의 숫자로, 즉 1차원으로 shape가 줄어든다.
앞의 CNN(Convolutional Neural Net)에서 점점 작은 feature map이 출력되다가, Flatten과 Dense 레이어를 거쳐 1차원으로 shape이 줄어드는 네트워크는 CNN을 사용한 딥러닝 모델의 가장 대표적인 형태라고 한다.

flatten()
flatten은 단어 그대로 납잡하게 만들어주는 느낌이다. 다음 예시를 보면 매우 쉽게 이해된다.
array([[1, 2],
[3, 4]])array([1, 2, 3, 4])flatten 레이어를 통과하면 2 X 2 행렬이 납작하게 일렬로 펼쳐 진다.
결국 flatten을 지난 후에 Dense 레이어에서 512개의 노드로 축소시켜 최종 출력은 단 두 개의 숫자로 구성된 하나의 확률분포를 내뱉게 된다. 이 두 숫자는 각각 강아지인지 고양이인지를 나타내는 것이다.
즉, 딥러닝 모델은 (160, 160, 3) 크기의 3차원 이미지를 입력받아 여러 레이어를 거치며 형태를 바꾸다가 최종적으로는 몇 개의 숫자를 출력해내는 함수라고 보면 된다.
Optimizer, loss, metrics, batch
learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])- optimizer(최적화 함수)는 학습을 어떤 방식으로 시킬 것인지 결정.
- loss는 모델이 학습해나가야 하는 방향을 결정. 이 문제에서는 모델의 출력은 입력받은 이미지가 고양이인지 강아지인지에 대한 확률분포로 두었으므로, 입력 이미지가 고양이(label=0)일 경우 모델의 출력이 [1.0, 0.0]에 가깝도록, 강아지(label=1)일 경우 [0.0, 1.0]에 가까워지도록 하는 방향을 제시
- metrics는 모델의 성능을 평가하는 척도. 분류 문제를 풀 때, 성능을 평가할 수 있는 지표는 정확도(accuracy), 정밀도(precision), 재현율(recall) 등이 있고, 여기서는 정확도를 사용했음.
Batch는 메모리의 한계와 속도 저하 문제를 해결해줄 수 있는 하나의 방법이다. Batch size 만큼의 데이터를 하나의 batch로 묶어서 일괄적으로 처리하는 방식이다. 그리고 이어서 학습을 시켜보면... 아래 그래프까지 얻을 수 있다.
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)EPOCHS = 10
history = model.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches)acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs_range = range(EPOCHS)
plt.figure(figsize=(12, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend()
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()
training accuracy는 지속적으로 증가하며 1에 가까워 지고 있는데, 계속 동일한 문제를 보고 풀게 되니 모델은 그 데이터에 최적화되어 간다. 그에 반해 validation accuracy 또한 증가하긴 하지만 어느 지점에서 부터는 제자리 걸음을 걷는 것 처럼 보인다. 그리고 loss값은 오히려 증가하고 있다. 여기서 Overfitting이라는 문제가 발생한 것을 알 수 있다. 말 그대로 계속 보던 훈련 데이터로만 학습을 진행하다보니 모델이 training set에 대해 과적합해진 상태이다. 이렇게 될 경우 오히려 test set에 대해 좋지 않은 성능을 낼 가능성이 매우 높기 때문에 valid set의 결과들을 보면서 과적합을 피하도록 모델을 훈련시킬 필요가 있다. (Epoch에 변화를 주거나 모델을 수정하는 방식 등의 방식으로 ...)
그리고 결과를 확인해보면?...
plt.figure(figsize=(20, 12))
for idx, (image, label, prediction) in enumerate(zip(images, labels, predictions)):
plt.subplot(4, 8, idx+1)
image = (image + 1) / 2
plt.imshow(image)
correct = label == prediction
title = f'real: {label} / pred :{prediction}\n {correct}!'
if not correct:
plt.title(title, fontdict={'color': 'red'})
else:
plt.title(title, fontdict={'color': 'blue'})
plt.axis('off')
count = 0 # 정답을 맞춘 개수
for image, label, prediction in zip(images, labels, predictions):
if label == prediction:
count += 1
print(count / 32 * 100) #결과 0.75
Transfer Learning(전이학습)
CV에서 전이학습은 사전학습 된 모델 (pre-trained model)을 이용해서 학습시키는 것을 의미한다. Pre-tained model은 이미 이전에 내가 풀고자 하는 문제와 비슷하고 사이즈가 큰 데이터로 이미 학습된 모델이다. 방대한 데이터로 모델을 학습시키는 것은 오랜 시간과 연산량이 필요하기 때문에 일반적으로 이미 공개되어있는 모델들을 import해서 사용한다 (ex. VGG, Inception, MobileNet).
역대 이미지넷 챌린지에서 우승한 모델들에 대한 참고자료.
ILSVRC 대회 (이미지넷 이미지 인식 대회) 역대 우승 알고리즘들
ILSVRC은 ImageNet Large Scale Visual Recognition Challenge의 약자로 이미지 인식(image recognition) 경진대회이다. 여기서 이미지 인식과 이미지 분류(image classification)는 같은 의미를 갖는다. 대용량..
bskyvision.com
Finetunning
사전 학습된 모델을 나의 목적에 맞게 수정을 해야하는데 우선은 나에게 맞는 classifier로 바꿔야하고, 그 후 마지막으로 다음 세 가지 전략 중 한 가지 방법을 이용해 파인튜닝(fine-tune)을 진행해야한다.
ㅤ
# 전략 1 : 전체 모델을 새로 학습시키기
이 방법은 사전학습 모델의 구조만 사용하면서, 내 데이터셋에 맞게 전부 새로 학습시키는 방법이다. 모델을 밑바닥에서부터 새로 학습시키는 것이므로, 큰 사이즈의 데이터셋이 필요하다. (그리고, 뛰어난 연산 환경도 준비되어야 한다!)
ㅤ
# 전략 2 : Convolutional base의 일부분은 고정시킨 상태로, 나머지 계층과 classifier를 새로 학습시키기
우선 층에 대한 얘기를 해야한다. 모델은 여러 층을 가지고 있는데 첫 번째 층은 "일반적인(general)" 특징을 추출하도록 하는 학습이 이루어지는 반면에, 모델의 마지막 층에 가까워질수록 특정 데이터셋 또는 특정 문제에서만 나타날 수 있는 "구체적인(specific)" 특징을 추출해내도록 하는 고도화된 학습이 이루어진다.
그래서! 이런 특성을 이용해서, 우리는 신경망의 파라미터 중 어느 정도까지를 재학습시킬지를 정할 수 있는데, 주로, 만약 데이터셋이 작고 모델의 파라미터가 많다면, 오버피팅이 될 위험이 있으므로 더 많은 계층을 건들지 않고 그대로 두는 편이 좋다. 반면에, 데이터셋이 크고 그에 비해 모델이 작아서 파라미터가 적다면, 오버피팅에 대한 걱정을 할 필요가 없으므로 더 많은 계층을 학습시켜서 내 프로젝트에 더 적합한 모델로 발전시키면 된다!
ㅤ
# 전략 3 : Convloutional base는 고정시키고, classifier만 새로 학습시키기
이 경우는 보다 극단적인 상황일 때 생각할 수 있는 케이스로 convolutional base는 건들지 않고 그대로 두면서 특징 추출 메커니즘으로써 활용하고, classifier만 재학습시키는 방법을 쓰는 것이다. 이 방법은 컴퓨팅 연산 능력이 부족하거나 데이터셋이 너무 작을때, 그리고/또는 내가 풀고자 하는 문제가 사전학습모델이 이미 학습한 데이터셋과 매우 비슷할 때 고려하면 좋다.

VGG-16
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
# Create the base model from the pre-trained model VGG16
base_model = tf.keras.applications.VGG16(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
base_model.summary() #VGG16가 출력하는 벡터의 Shape는 [32, 5, 5, 512]VGG 모델에 대해 간략하게 얘기하면, 우선 맨 처음에 보던 모델에 비해 층이 굉장히 많은데, 특히! 마지막 층에서 사이즈가 [5, 5, 512]로 출력된다. height, width는 줄었지만 채널수가 엄청 커졌다.(32는 batch size다.)
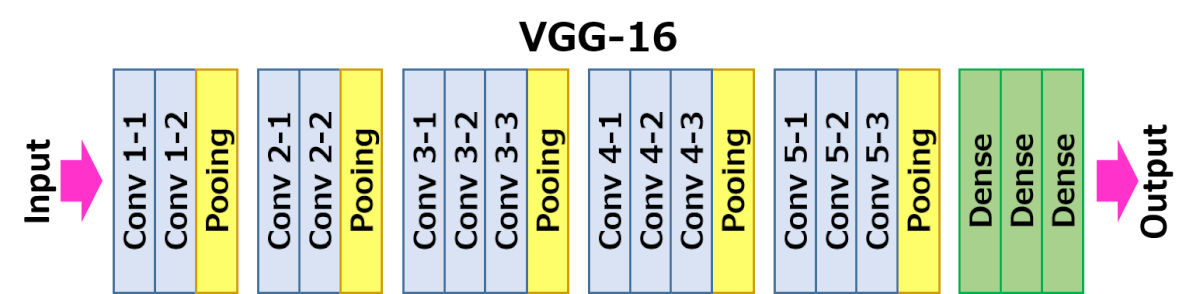
그래서 3차원의 벡터를 이제 마지막에 쫙 펴주는 처리를 해줘야하는데, 이전에 flatten에 대해 이미 언급을 했다. 근데 이번엔 더 좋은 방법이라고 평가받는 Global Average Pooling의 방법을 쓰면 좋을 것 같다. 자세한 설명은 링크로 ...
2D Global average pooling | Peltarion Platform
2D Global average pooling takes a tensor and computes the average value of all values across the entire matrix for each of the input channels.
peltarion.com
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
# feature_batch_average = global_average_layer(feature_batch)
# print(feature_batch_average.shape) 이 부분으로 테스트해보면 (32, 512)가 나옴.
dense_layer = tf.keras.layers.Dense(512, activation='relu')
prediction_layer = tf.keras.layers.Dense(2, activation='softmax')
base_model.trainable = False
model = tf.keras.Sequential([
base_model,
global_average_layer,
dense_layer,
prediction_layer
])
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
EPOCHS = 5 # 이번에는 이전보다 훨씬 빠르게 수렴되므로 5Epoch이면 충분합니다.
history = model.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches)위과 같이 구현하면 아주 쉽게 정확도가 90%가 넘어가게 된다. 이런게 pre-tained model의 힘인 것 같다. 그리고 마지막으로 얘기하고 싶은 것은 save와 load다. 즉 이렇게 학습시켜서 현재 파라미터를 그대로 유지하고 싶다면 저장을 해야하는데 그 방법은 다음과 같다.
모델 save & load
모델 저장과 복원 | TensorFlow Core
도움말 Kaggle에 TensorFlow과 그레이트 배리어 리프 (Great Barrier Reef)를 보호하기 도전에 참여 모델 저장과 복원 모델 진행 상황은 훈련 중 및 훈련 후에 저장할 수 있습니다. 즉, 모델이 중단된 위치
www.tensorflow.org
'AI,ML,DL' 카테고리의 다른 글
| repeat, shuffle, batch에 관하여 (0) | 2022.03.31 |
|---|---|
| PetFinder.my - Pawpularity Contest(캐글 코드 리뷰-ViT+CLs) (0) | 2022.02.08 |
| 데이터 시각화와 전처리(kaggle 포켓몬 데이터) (2) | 2022.01.14 |
- Total
- Today
- Yesterday
- K-Digital
- 삶 #성공
- 데이터전처리
- python #패러다임
- 분류기
- 강아지고양이분류기
- 아이펠
- cnn
- 포켓몬
- 텐서플로우
- AIFFEL
- 토스 #독서 #유난한도전 #스타트업
- EDA
- GAN #FID #StyleGAN #StyleGAN2
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |