
티스토리 뷰
우선 이번에 사용할 Data는 캐글의 데이터다.
Pokemon with stats
721 Pokemon with stats and types
www.kaggle.com
이번 분석의 목표 : 전설의 포켓몬인지 아닌지를 맞춰보자!
우선 처음에 쓸 라이브러리들과 기본적인 데이터 상태를 살펴보자.
데이터 확인하기(1)
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import os
csv_path = os.getenv("HOME") +"/pokemon_eda/data/Pokemon.csv"
original_data = pd.read_csv(csv_path)
pokemon = original_data.copy()
print(pokemon.shape) #output -> (800, 13)
legendary = pokemon[pokemon["Legendary"] == True].reset_index(drop=True)
print(legendary.shape) #output -> (65, 13)살펴보니 800종의 포켓몬을 분석하게 될 거고, 그 중에 65종이 전설의 포켓몬이다. 한마디로 불균형한 데이터고 전설의 포켓몬 여부를 맞추는 학습에서 accuracy가 평가지표로서 크게 중요하지 않게 된다.
결측치 체크를 해보면 Type2에만 386개의 결측치가 있는데, 이 부분은 포켓몬 게임을 해봤다면 바로 이해가 될 것이다. 그냥 포켓몬마다 고유의 속성을 지니는데, 어떤 종은 멀티 속성을 지니고 있어 더 강력하면서 약점도 많아지는 그런 식의 게임 시스템이다. 어쨌든 결측치 처리는 나중에 해줘야한다.
Columns
칼럼들을 한번 살펴보자.
print(len(pokemon.columns))
pokemon.columns
13
Index(['#', 'Name', 'Type 1', 'Type 2', 'Total', 'HP', 'Attack', 'Defense',
'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary'],
dtype='object')#, Name, Type1,2 등 여러가지의 feature들이 있는데 우선 #은 고유 넘버로 크게 필요해보이지 않을 것만 같다. Legendary 부분은 target feature로 쓸 부분이고, str타입의 칼럼 Name, Type1, Type2을 제외하고는 모두 int 타입이다. (위에서 pokemon.head()로 데이터를 살펴보면 알 수 있다.)
pokemon.isnull().sum()
# 0
Name 0
Type 1 0
Type 2 386
Total 0
HP 0
Attack 0
Defense 0
Sp. Atk 0
Sp. Def 0
Speed 0
Generation 0
Legendary 0
dtype: int64중독된 자료는 없는지 대략 살펴보면 len(set(pokemon["Name"])) 으로 모든 이름들을 set안에 넣어서 중복된 요소를 확인하고 len로 길이를 확인해보면 줄어들지 않고 800이 그대로 임을 통해서 중복은 없다는 것을 알 수 있다.
시각화
plt.figure(figsize=(10, 7)) # 화면 해상도에 따라 그래프 크기를 조정해 주세요.
plt.subplot(212)
sns.countplot(data=ordinary, x="Type 1", order=types).set_xlabel('')
plt.title("[Ordinary Pokemons]")
plt.subplot(211)
sns.countplot(data=legendary, x="Type 1", order=types).set_xlabel('')
plt.title("[Legendary Pokemons]")
plt.show() |
 |
왼쪽부터 각각 Type1, 2에 대한 분포 막대그래프
그래프를 통해 보면 전설과 일반 포켓몬의 타입 차이도 어느 정도 느껴진다. 전설은 Psychic, Dragon타입이 많다. 그에 반해 일반은 벌레, 물, 풀, 일반 타입의 포켓몬이 많고, Flying타입은 공통적으로 많다. Type이 어떤 포켓몬인지를 판별하는 중요한 기준이 될 수 있을 것 같다.
def tokenize(name):
name_split = name.split(" ")
tokens = []
for part_name in name_split:
a = re.findall('[A-Z][a-z]*', part_name)
tokens.extend(a)
return np.array(tokens)
데이터 확인하기(2)
포켓몬 하나의 정보를 나타내는 것은 사실상 stats가 전부라고 해도 봐도 무방한데, 우선 stats안으로 스탯 요소들을 모두 묶어주고 더해보자. 그리고 총합과 비교해보면?
stats = ["HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", "Speed"]
print("#0 pokemon: ", pokemon.loc[0, "Name"])
print("total: ", int(pokemon.loc[0, "Total"]))
print("stats: ", list(pokemon.loc[0, stats]))
print("sum of all stats: ", sum(list(pokemon.loc[0, stats])))#0 pokemon: Bulbasaur
total: 318
stats: [45, 49, 49, 65, 65, 45]
sum of all stats: 318같게 나온다^^ 그래도 전체를 확인해봐야하니 stats의 총합과 Total 칼럼의 값과 같은 포켓몬의 개수를 출력해보면?
뭐 뻔하게도 800이다.
sum(pokemon['Total'].values == pokemon[stats].values.sum(axis=1)) # 800
Total값에 따른 전설 포켓몬의 분포도 한번 살펴보면 좋을 것 같다. 전설 포켓몬은 능력치가 사기일 가능성이 높으니까?
fig, ax = plt.subplots()
fig.set_size_inches(12, 6) # 화면 해상도에 따라 그래프 크기를 조정해 주세요.
sns.scatterplot(data=pokemon, x="Type 1", y="Total", hue="Legendary")
plt.show()
주황색 점들이 전설의 포켓몬인데 상위권에 위치하는 것을 확인할 수 있다. 그럼 이제 남은게 세대, Total값 그리고 이름정도인데 세대는 그냥 생략하도록 하자. 분명 일종의 황금기처럼 전설의 포켓몬이 우르르 나온 세대가 존재하겠지만 그냥 그정돈 무시하자.
Total 값은 아까도 살짝 봤지만 꽤나 중요한 지표이다. 왜냐하면 일정 토탈 능력치가 넘어가면 무조건 전설의 포켓몬이게 되고 심지어 650정도만 넘어가도 한마리 빼고는 모두 전설이다. 이 부분도 더 상세히 살펴볼 수 있지만 이정도만 체크하겠다.
그럼 이름! 요기서는 몇가지 스킬을 사용할 겸 좀 자세하게 볼 필요가 있다.
n1, n2, n3, n4, n5 = legendary[3:6], legendary[14:24], legendary[25:29], legendary[46:50], legendary[52:57]
names = pd.concat([n1, n2, n3, n4, n5]).reset_index(drop=True)
names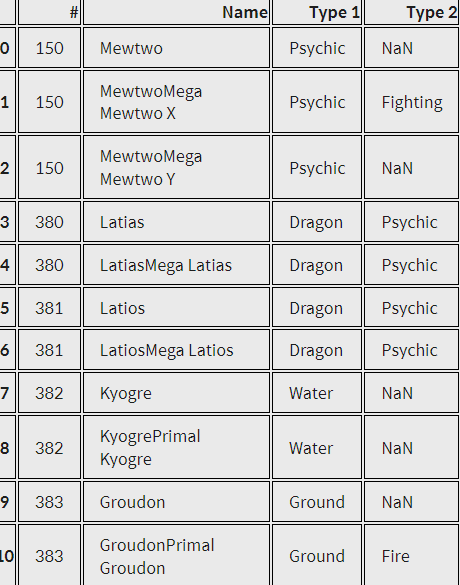
전설의 포켓몬들은 이름이 세트로 지어진 것들이 많다. (사실 이건 전설의 포켓몬만의 특징은 아니지만...)
그리고 또 forme라는 단어가 들어가는 이름은 전설의 포켓몬이다.
이 부분은 확실히 중요한 데이터다.
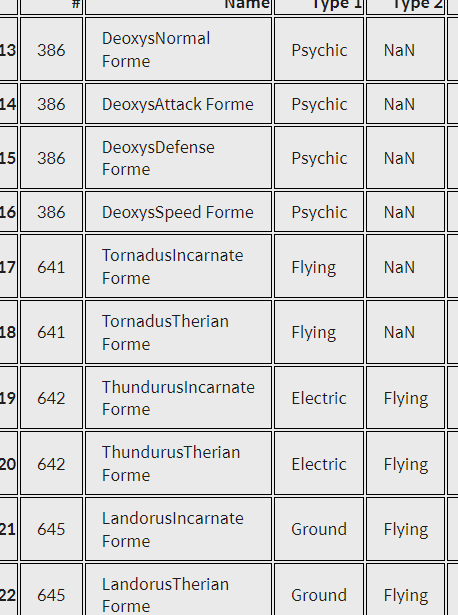
formes = names[13:23]
formes
그리고 또 한가지 포인트가 있다면 전설의 포켓몬은 이름이 좀 긴 것 같다. 그래서 이름의 글자수를 세어주는 칼럼을 추가해줘도 좋을 듯 하다.
legendary["name_count"] = legendary["Name"].apply(lambda i: len(i))
ordinary["name_count"] = ordinary["Name"].apply(lambda i: len(i))
plt.figure(figsize=(12, 10)) # 화면 해상도에 따라 그래프 크기를 조정해 주세요.
plt.subplot(211)
sns.countplot(data=legendary, x="name_count").set_xlabel('')
plt.title("Legendary")
plt.subplot(212)
sns.countplot(data=ordinary, x="name_count").set_xlabel('')
plt.title("Ordinary")
plt.show()
실제로 name_count로 분포를 보면 전설의 포켓몬 이름들이 긴 것을 확인할 수 있다. 10자 이상인 전설의 포켓몬의 비율은 무려 41.54%가 나온다. 그래서 name_count 말고도 추가로 long_name을 추가해보자. 10자 이상이면 long_name이 True가 되는 칼럼을 추가하는 것이다.
pokemon["long_name"] = pokemon["name_count"] >= 10
Tokenize
이 부분을 위해서 Name까지 살펴보려고 한건데, Name의 모양을 좀 이쁘게 다듬을 필요가 있다. 그래서 띄어쓰기를 없애고 isalpha()를 통해 이름에 특수문자가 포함된 것들을 골라냈다. 그리고 적절한 문자로 다시 바꿔주기까지... 힘들다^^
pokemon["Name_nospace"] = pokemon["Name"].apply(lambda i: i.replace(" ", ""))
pokemon["name_isalpha"] = pokemon["Name_nospace"].apply(lambda i: i.isalpha())
print(pokemon[pokemon["name_isalpha"] == False].shape)
pokemon[pokemon["name_isalpha"] == False]
# 특수문자가 포함된 녀석들만 손수 고쳐주었다.
pokemon = pokemon.replace(to_replace="Nidoran♀", value="Nidoran X")
pokemon = pokemon.replace(to_replace="Nidoran♂", value="Nidoran Y")
pokemon = pokemon.replace(to_replace="Farfetch'd", value="Farfetchd")
pokemon = pokemon.replace(to_replace="Mr. Mime", value="Mr Mime")
pokemon = pokemon.replace(to_replace="Porygon2", value="Porygon")
pokemon = pokemon.replace(to_replace="Ho-oh", value="Ho Oh")
pokemon = pokemon.replace(to_replace="Mime Jr.", value="Mime Jr")
pokemon = pokemon.replace(to_replace="Porygon-Z", value="Porygon Z")
pokemon = pokemon.replace(to_replace="Zygarde50% Forme", value="Zygarde Forme")
그럼 진짜로 tokenize를 진행하자. 이름을 조각조각내는 토큰화 작업을 하는 이유는 각각의 어떤 단어가 전설의 포켓몬에서 발견되는지를 살펴보는 것이 진짜 목적이다.
import re
def tokenize(name):
name_split = name.split(" ")
tokens = []
for part_name in name_split:
a = re.findall('[A-Z][a-z]*', part_name)
tokens.extend(a)
return np.array(tokens)
name = "CharizardMega Charizard X"
tokenize(name) #output -> array(['Charizard', 'Mega', 'Charizard', 'X'], dtype='<U9')
all_tokens = list(legendary["Name"].apply(tokenize).values)
token_set = []
for token in all_tokens:
token_set.extend(token)
print(len(set(token_set)))
print(token_set)
가장 빈번하게 나타나는 토큰을 10가지 뽑아서 보면 아래와 같고 이를 칼람을 각각 생성하고 True or False로 채워보자.
Counter(), str.contains()
most_common = Counter(token_set).most_common(10)
most_common[('Forme', 15),
('Mega', 6),
('Mewtwo', 5),
('Kyurem', 5),
('Deoxys', 4),
('Hoopa', 4),
('Latias', 3),
('Latios', 3),
('Kyogre', 3),
('Groudon', 3)]
for token, _ in most_common:
# pokemon[token] = ... 형식으로 사용하면 뒤에서 warning이 발생합니다
pokemon[f"{token}"] = pokemon["Name"].str.contains(token)
pokemon.head(10)
결과의 표처럼 각 토큰마다 Bool데이터로 체크해서 열이 추가된다.
One-Hot Encoding / Integer Encoding
Type1,2는 범주형 데이터다. 범주형 데이터는 숫자로 모든 것을 처리하는 컴퓨터 입장에서 학습하는데 굉장히 불리하다. 그래서 이를 숫자로 바꿔줘야하는데, 범주형 데이터를 정수형으로 바꾸는 방법이 대표적으로 두가지 있다. Integer Encoding은 fire, ice, grass 등의 타입을 0,1,2,... 으로 바꿔준다. 근데 문제가 있다! 숫자에 대소 관계가 생긴다. 대소 관계가 크고 작은 정도를 만들기도 하지만 각 타입간의 간격도 생성된다. 예를 들어, fire : 0, ice : 1, grass : 2인 상황에서 fire가 grass보다 ice랑 가까운 관계가 된다. 그래서 포켓몬의 type 데이터 같이 수평적인 관계에서는 좋은 방식이 아니다.
이런 데이터에서는 one-hot encoding을 써주는 것이 좋다. 모든 범주를 칼럼으로 생성한 후에 각 범주마다 True인지 False인지를 판별하여 값을 대입하는 방식이다.
for t in types:
pokemon[t] = (pokemon["Type 1"] == t) | (pokemon["Type 2"] == t) #pandas에서는 |나 &를 쓴다.
pokemon[[["Type 1", "Type 2"] + types][0]].head()
비트연산자와 논리연산자
python and pandas Operator - Bitwise Operator : &, |, ~, ^, df.any(), df.all() - Logical Operator : and, or, not, xor, any, all 궁금한 점 and와 &는 같은 연산자일텐데 왜 1과 2를 비교하는데에 있어서..
sozerodev.tistory.com
Result
이제 결론이다! 우선 원래 데이터가지고 결과를 한번 살펴보자.
X = original_data[features]
y = original_data[target]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=15)
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=25)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred)) precision recall f1-score support
False 0.97 0.98 0.97 147
True 0.73 0.62 0.67 13
accuracy 0.95 160
macro avg 0.85 0.80 0.82 160
weighted avg 0.95 0.95 0.95 160정확도가 95%지만 불균형 데이터라 다 일반 포켓몬으로 찍어도 정확도가 92%가 나온다. 즉 유심히 봐야할 부분은 recall값. 0.62로 많이 낮게 나왔다. 하지만 최종 데이터로 다시 학습하게 되면 recall 값이 0.92까지 상승한다!!!
precision recall f1-score support
False 0.99 0.96 0.98 147
True 0.67 0.92 0.77 13
accuracy 0.96 160
macro avg 0.83 0.94 0.87 160
weighted avg 0.97 0.96 0.96 160
이렇게 EDA와 preprocessing 해주는 과정이 중요하다는 것을 살펴 볼 수 있었고 이 부분 스킬들은 지속적으로 자주 연습해줘야 할 것 같다.
'AI,ML,DL' 카테고리의 다른 글
| repeat, shuffle, batch에 관하여 (0) | 2022.03.31 |
|---|---|
| PetFinder.my - Pawpularity Contest(캐글 코드 리뷰-ViT+CLs) (0) | 2022.02.08 |
| CNN모델에 대하여 : dogs&cats classifier (0) | 2022.01.12 |
- Total
- Today
- Yesterday
- 아이펠
- AIFFEL
- 데이터전처리
- EDA
- 강아지고양이분류기
- 포켓몬
- 토스 #독서 #유난한도전 #스타트업
- 삶 #성공
- cnn
- K-Digital
- 분류기
- python #패러다임
- 텐서플로우
- GAN #FID #StyleGAN #StyleGAN2
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |